|
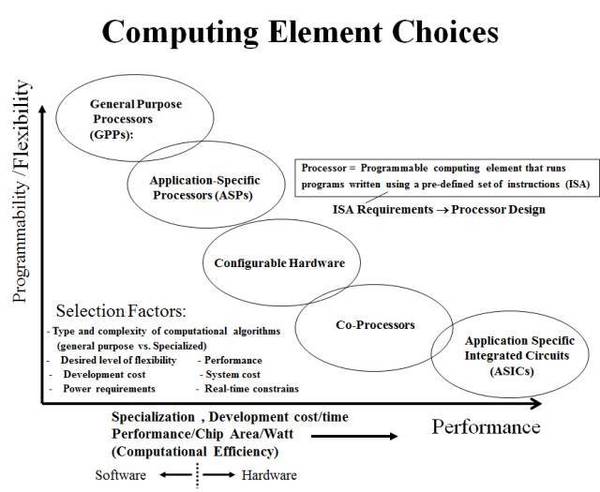
做了这么多年芯片,像AI芯片这样备受关注的情况还是第一次看到。这段时间随着Volta和TPU2的发布,“GPU好还是TPU好”的争论又热了起来,也有很多断言性的结论。这样的争论真的有意义吗? 我们先看一张图,它来自RIT的Shaaban教授的计算机体系结构课程,比较各种computing elements。其中,他把GPU,DSP归为ASP,TPU大概的位置是Co-processor这一类。FPGA则是一种Configurable Hardware。
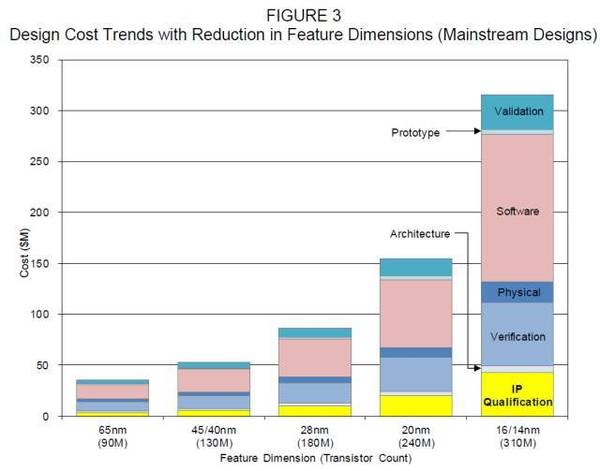
实际上,今天大家吵的厉害的CPU,GPU,DSP,TPU(第一代采用脉动阵列架构),FPGA这些架构并不新鲜,都是体系结构领域研究多年的内容。除了GPP(General Purpose Processors,通用处理器,或者我们一般意义上说的CPU),这些架构的发明,往往是针对特定应用或者特殊目标的。从这些架构在图中的分布可以看出,每个架构都是Trade-off的结果,Computational Efficiency的提高是以牺牲Programmability/Flexibility为代价的。 具体到AI应用,是不是可以说TPU就比GPU好,或者反之呢? 我们不妨再来看另一张图,它来自International Business Strategies, Inc. (IBS)2014年发布的报告 "Strategies in Optimizing Market Positions for Semiconductor Vendors Based on IP Leverage"。它说明的是在主流的芯片设计中,随着工艺节点的演进,设计成本变化的趋势和分布(不包括生产成本)。
从这里不难看出,我们在一个芯片项目中各个任务需要的投入(cost)。显然,其中最大的部分是Software,Verification和Validation。而Architecture设计只占其中的很小一部分。这个比例和目前大多数芯片厂商的人员配置也是基本相符的。形成这种趋势,是因为现在的芯片往往只是一个复杂系统中的一部分。芯片设计厂商(或者方案商)提供给客户的已经远远不止芯片本身,而是一套完整的软硬件解决方案。Nvidia在Deep learning上的巨大成功,是归功于它的芯片底层硬件架构,还是它完善的软硬件生态呢?当然是后者。Google之所以敢于和能够自己设计TPU芯片,是和Tensorflow布局和以及data center方面的经验分不开的。绝大多数deep learning用户看到的是Tensorflow(或者其它训练框架)和CUDA,而不是底层硬件(只要硬件别太昂贵)。 由于目前的计算系统,比如说Deep Learning的系统,是一个相当复杂的软硬件系统。要公平的对比不同的芯片硬件架构反映到最终应用层面上的优劣,是一件非常困难的事情。从不同的角度或者立场出发,大家可能会看到完全不同的结果。此处想起前段时间的段子,“拳击跟太极谈实战,太极跟拳击谈历史;空手道跟太极谈实战,太极跟空手道谈武德;柔术跟太极谈实战,太极跟柔术谈观赏;泰拳跟太极谈实战,太极跟泰拳谈养生;瑜伽跟太极谈养生,太极‘来,我们谈谈实战。’ ”真不是黑太极,不过如果大家可以直接“对战”,也就没有打嘴仗的必要了。 决定我们的AI芯片是否成功的因素到底是什么?仅仅是因为你选择了Nvidia GPU采用的硬件架构或者是Google TPU的脉动阵列架构吗?还是你发明了一种新的架构?当然不是。架构的选择和设计应该服务于整个系统和项目,需要对很多因素做Trade-off和Optimiztion。从技术角度来看,如果把一个芯片应用分成,算法/软件,硬件架构,电路实现,几个从高到低的基本层次。那么高层次上的优化,对于整个系统的效果往往比低层次高一个数量级。(当然,这是个一般经验,atv直播,针对不同类型的项目会有一定差异) 很多时候,atv,这种Trade-off甚至都不是技术本身的问题。比如,Google在芯片设计上的实力和Nvidia相比相差很远,从硬件相对简单的脉动阵列做起就是个比较自然的选择。而在Google TPU的论文里也明确提到,由于项目时间比较紧,很多优化也只能放弃()。 “Under The Hood Of Google’s TPU2 Machine Learning Clusters”,这篇文章对Google TPU2现有的信息做了非常深入的分析,作者从Google提供的仅有的几张照片中发掘出大量信息。其中有这样的描述: “This tight coupling of TPU2 accelerators to processors is much different than the 4:1 to 6:1 ratios typical for GPU accelerators in deep learning training tasks. The low 2:1 ratio suggests that Google kept the design philosophy used in the original TPU: “the TPU is closer in spirit to an FPU (floating-point unit) coprocessor than it is to a GPU.” The processor is still doing a lot of work in Google’s TPU2 architecture, but it is offloading all its matrix math to the TPU2.” (责任编辑:本港台直播) |