|
由腾讯云基础产品中心、腾讯架构平台部组成的腾讯云FPGA联合团队,在这里介绍国内首款FPGA云服务器的工程实现深度学习算法(AlexNet),讨论深度学习算法FPGA硬件加速平台的架构。 背景是这样的:在1 月 20 日,腾讯云推出国内首款高性能异构计算基础设施——FPGA 云服务器,将以云服务方式将大型公司才能长期支付使用的 FPGA 普及到更多企业,企业只需支付相当于通用CPU约40%的费用,性能可提升至通用CPU服务器的30倍以上。具体分享内容如下: 1. 综述 2016年3月份AI围棋程序AlphaGo战胜人类棋手李世石,点燃了业界对人工智能发展的热情,人工智能成为未来的趋势越来越接近。 人工智能包括三个要素:算法,计算和数据。人工智能算法目前最主流的是深度学习。计算所对应的硬件平台有:CPU、GPU、FPGA、ASIC。由于移动互联网的到来,用户每天产生大量的数据被入口应用收集:搜索、通讯。我们的QQ、微信业务,用户每天产生的图片数量都是数亿级别,如果我们把这些用户产生的数据看成矿藏的话,计算所对应的硬件平台看成挖掘机,挖掘机的挖掘效率就是各个计算硬件平台对比的标准。 最初深度学习算法的主要计算平台是 CPU,因为 CPU 通用性好,硬件框架已经很成熟,对于程序员来说非常友好。然而,当深度学习算法对运算能力需求越来越大时,人们发现 CPU 执行深度学习的效率并不高。CPU 为了满足通用性,芯片面积有很大一部分都用于复杂的控制流和Cache缓存,留给运算单元的面积并不多。这时候,GPU 进入了深度学习研究者的视野。GPU原本的目的是图像渲染,图像渲染算法又因为像素与像素之间相对独立,GPU提供大量并行运算单元,可以同时对很多像素进行并行处理,而这个架构正好能用在深度学习算法上。 GPU 运行深度学习算法比 CPU 快很多,但是由于高昂的价格以及超大的功耗对于给其在IDC大规模部署带来了诸多问题。有人就要问,如果做一个完全为深度学习设计的专用芯片(ASIC),会不会比 GPU 更有效率?事实上,要真的做一块深度学习专用芯片面临极大不确定性,首先为了性能必须使用最好的半导体制造工艺,而现在用最新的工艺制造芯片一次性成本就要几百万美元。去除资金问题,组织研发队伍从头开始设计,完整的设计周期时间往往要到一年以上,但当前深度学习算法又在不断的更新,设计的专用芯片架构是否适合最新的深度学习算法,风险很大。可能有人会问Google不是做了深度学习设计的专用芯片TPU?从Google目前公布的性能功耗比提升量级(十倍以上的提升)上看,还远未达到专用处理器的提升上限,因此很可能本质上采用是数据位宽更低的类GPU架构,j2直播,可能还是具有较强的通用性。这几年,FPGA 就吸引了大家的注意力,亚马逊、facebook等互联网公司在数据中心批量部署了FPGA来对自身的深度学习以云服务提供硬件平台。 FPGA 全称「可编辑门阵列」(Field Programmable Gate Array),其基本原理是在 FPGA 芯片内集成大量的数字电路基本门电路以及存储器,而用户可以通过烧写 FPGA 配置文件来来定义这些门电路以及存储器之间的连线。这种烧入不是一次性的,即用户今天可以把 FPGA 配置成一个图像编解码器,明天可以编辑配置文件把同一个 FPGA 配置成一个音频编解码器,这个特性可以极大地提高数据中心弹性服务能力。所以说在 FPGA 可以快速实现为深度学习算法开发的芯片架构,而且成本比设计的专用芯片(ASIC)要便宜,当然性能也没有专用芯片(ASIC)强。ASIC是一锤子买卖,设计出来要是发现哪里不对基本就没机会改了,但是 FPGA 可以通过重新配置来不停地试错知道获得最佳方案,所以用 FPGA 开发的风险也远远小于 ASIC。 2. Alexnet 算法分析2.1 Alexnet模型结构 Alexnet模型结构如下图2.1所示。
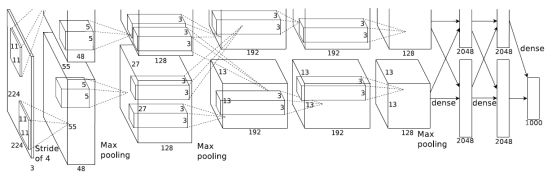
图2.1 Alexnet模型 模型的输入是3x224x224大小图片,采用5(卷积层)+3(全连接层)层模型结构,部分层卷积后加入Relu,Pooling 和Normalization层,最后一层全连接层是输出1000分类的softmax层。如表1所示,全部8层需要进行1.45GFLOP次乘加计算,计算方法参考下文。 层数 kernel个数 每个kernel进行卷积次数 每个kernel一次卷积运算量 浮点乘加次数 第1层 96 3025 (1x363)x(363x1) 96x3025x363=105M=210MFLOP 第2层 256 729 (1x1200)x(1200x1) 256x729x1200=224M=448MFLOP 第3层 384 169 (1x2304)x(2304x1) 384x169x2304=150M=300MFLOP 第4层 384 169 (1x1728)x(1728x1) 384x169x1728=112M=224MFLOP 第5层 256 169 (1x1728)x(1728x1) 256x169x1728=75M=150MFLOP 第6层 1 4096 (1x9216)x(9216x1) 4096x9216=38M=76MFLOP 第7层 1 4096 (1x4096)x(4096x1) 4096x4096=17M=34MFLOP 第8层 1 1000 (1x4096)x(4096x1) 1000x4096=4M=8MFLOP 总和 1.45GFLOP 表2.1 Alexnet浮点计算量 2.2 Alexnet 卷积运算特点 (责任编辑:本港台直播) |