|
先是CPU,后来是GPU。接下来是什么?人工智能芯片怎么样? 要是你还没有听说过使用深度神经网络和深度学习来处理从语音识别到实现自动驾驶汽车各项任务的人工智能和机器学习热潮,那么恐怕还没有听说过谷歌新的Tensor处理单元(TPU)、英特尔的Lake Crest或者Knupath的Hermosa。多家厂商期望提供针对神经网络的平台,这些只是其中的几个代表。 谷歌TPU TPU含有一个庞大的8位矩阵乘法单元(见图1)。它实际上优化了DNN所需要的数字处理,因而不需要大型的浮点数字系统。
图1:谷歌的TPU有一个庞大的8位矩阵乘法单元,atv直播,帮助它为深度神经网络处理数字。 TPU实际上是由传统主机CPU通过TPU的PCI Express接口来管理的一种协处理器。TPU芯片的运行速度只有700 MHz,不过说到DNN加速,它却可以击败CPU和GPU系统。虽然没有明确作为一种DNN处理器,但是它可以处理繁重任务,耗电量却只有40瓦。它有28 MB的板载内存以及4MB内存(表现为32位累加器用来编译来自矩阵乘法单元的16位结果)。该芯片使用28纳米工艺,晶片尺寸约600 平方毫米。《分析Tensor处理单元在数据中心中的性能》(https://drive.google.com/file/d/0Bx4hafXDDq2EMzRNcy1vSUxtcEk/view)一文介绍了更多的技术细节。 TPU板卡(图2)的执行速度可达到92 TeraOps/s(TOPS)。这比处理同一任务的CPU和GPU快15倍至30倍,每瓦TOPS方面提升30倍至80倍。用来比较系统的软件是TensorFlow框架。
图2:谷歌的TPU模块旨在将一排排插槽插入到云数据中心。 要牢记的一个方面是,TPU比较是针对局限性方面进行的。大多数CPU是64位平台,GPU可能拥有更宽的字宽。它们还往往针对更庞大的数据项进行了优化,不过大多数系统支持比较小的字(包括8位向量运算)。同样,不同的神经网络应用得益于不同的配置,但是比较小的8位整数已广泛应用于许多DNN应用。 TPU有五种主要的指令: Read_Host Read_Weights 矩阵乘法/卷积 激活 Write_Host 宽度是神经网络里面的值,被矩阵乘法单位所使用。激活函数为人工神经元执行非线性操作。 谷歌的TPU有望减少对更庞大数据中心的需要,不然,这种数据中心需要多得多的CPU和GPU来处理人工智能应用,应用领域广泛:从语音识别及分析、图像及视频处理、通过搜索提供服务,到那些小巧的Google Home系统,不一而足。 英特尔Lake Crest Lake Crest(图3)是旨在补充多核至强Phi的英特尔平台的代号。至强Phi负责处理许多人工智能事务,但是面对谷歌的TPU或英特尔的Lake Crester可以更高效地轻松处理的应用时却显得力不从心。Lake Crest技术最初是由Nervana开发的,这家公司并不隶属英特尔。
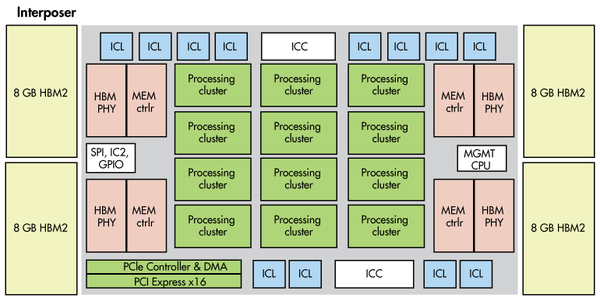
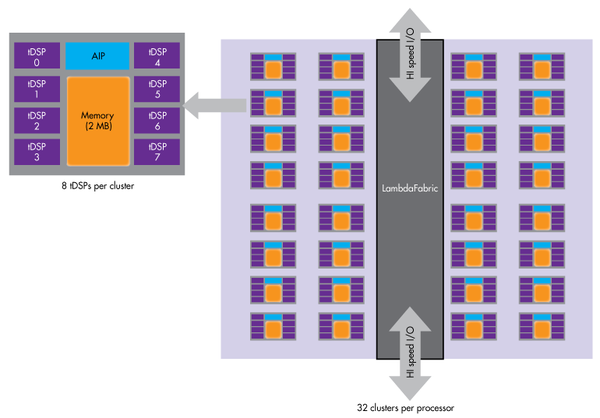
图3:英特尔的 Lake Crest使用针对人工智能应用而优化的处理集群。 新芯片将采用众多先进的功能特性,从多芯片模块(MCM)设计,到“Flexpoint”架构(拥有十多个专门的多核处理节点,类似TPU的矩阵乘法单元),不一而足。该芯片会有32 GB的高带宽内存2(HBM2),通过中介层(interposer),可获得8 TB/s的聚合带宽。HBM2在高性能的片上系统(SoC)和GPU中司空见惯。Lake Crest没有任何缓存。软件将用来优化内存管理。 Lake Crest预计会在2017年面市。 Knupath Hermosa Knupath的Hermosa(图4)拥有64个DMA引擎和256个数字信号处理(DSP)核心,组织成8个集群,每个集群的8个核心由Lambda Fabric加以连接。Lambda Fabric还旨在以一种低延迟、高吞吐量的网状网来连接成千上万个Hermosa处理器。
图4:Knupath的Hermosa多核处理器有256个DSP核心,这些核心采用8个集群来组织,每个集群的8个核心由Lambda Fabric加以连接。 Hermosa有一只集成的L1路由器,拥有32个端口和1 Tbps带宽。对外连接包括16个10 Gbps双向端口。该芯片有72 MB数据内存(分成32排)和2MB程序内存。 虽然Hermosa面向人工智能应用,但是相比更专用的Lake Crest或TPU平台,它却更加类似多核至强Phi。Hermosa可提供每秒3840亿次浮点运算(384 GFLOPS)的计算能力,耗电量却只有34瓦,因而非常适合一系列广泛的应用,而不仅仅是人工智能应用。 GPGPU继续唱主角(眼下) (责任编辑:本港台直播) |