|
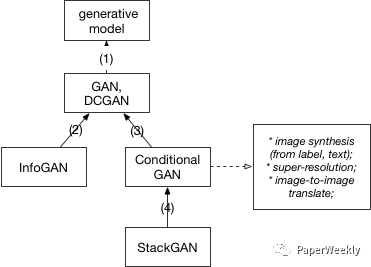
1、Unsupervised learning 首先我们从generative model说起。generative model的目的是找到一个函数可以最大的近似数据的真实分布。如果我们用 f(X; ??) 来表示这样一个函数,那么找到一个使生成的数据最像真实数据的 ?? 就是一个maximum likelihood estimation的过程。问题在于,当数据的分布比较复杂时,我们需要的 f 也会变复杂。现在我们有深度网络结构可以表达这样一个复杂的函数(deep generative model),但是训练过程成为了关键。基于sampling的训练过程显然不是很高效的。因此,如何设计模型以便利用backpropagation来训练网络成为了一个重要的目标。当前两个比较突出的模型实现的就是这个目的,一个是variational autoencoder(VAE),另一个就是这篇文章的主题generative adversarial nets。 这篇文章会从基本的GAN模型讲起,重点讨论模型公式背后的原理。之后会讨论几篇GAN的扩展工作,希望能够扩展一下大家的思路,也可以加深对GAN模型的理解。下面的关系图大致描述了这些模型之间的继承关系。我们会按照图中的关系一个一个展开。
2、GAN 首先是最经典的GAN模型。由Ian Goodfellow和Bengio等在2014年提出。为了简明扼要,我们直接看图说话。
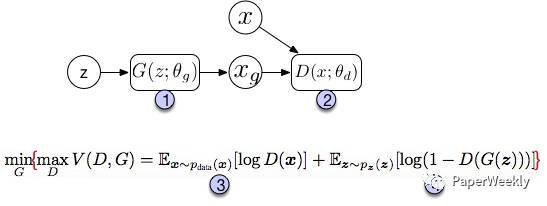
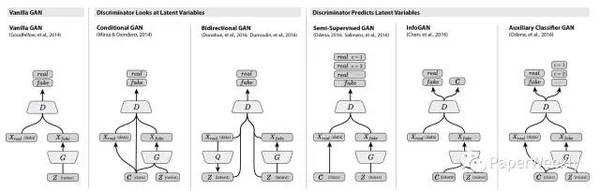
图中上半部分是GAN模型的基本架构。我们先从一个简单的分布中采样一个噪声信号 z(实际中可以采用[0, 1]的均匀分布或者是标准正态分布),然后经过一个生成函数后映射为我们想要的数据分布 Xg (z 和 X 都是向量)。生成的数据和真实数据都会输入一个识别网络 D。识别网络通过判别输出一个标量,表示数据来自真实数据的概率。在实现上,G 和 D 都是可微分函数,都可以用多层神经网络实现。因此上面的整个模型的参数就可以利用backpropagation来训练得到。 图中的下半部分是模型训练中的目标函数。仔细看可以发现这个公式很像cross entropy,注意D是 P(Xdata) 的近似。对于 D 而言要尽量使公式最大化(识别能力强),而对于 G 又想使之最小(生成的数据接近实际数据)。整个训练是一个迭代过程,但是在迭代中,对 D 的优化又是内循环。所以每次迭代,D 先训练 k次,G 训练一次。 GAN模型最大的优势就是训练简单,但是也有缺点比如训练的稳定性。有趣的是,在这篇文章future work部分,作者提出了5个可能扩展的方向,而现在回过头来看,后续的很多工作真的就是在照着这几个思路填坑。比如第一个conditional generative model就是后面要讲的conditional GAN的思路,而最后一个determing better distribution to sample z from during training则是后面InfoGAN的思路。 下面是来自twitter[9] 的一幅图,很好的总结了各种衍生模型的结构。
2.1 DCGAN 上面Ian J. Goodfellow等人的文章提出了GAN的模型和训练框架,但是没有描述具体的实现,而DCGAN[2] 这篇文章讲的就是用deep convolutional network实现一个生成图片的GAN模型。这篇文章没有在基本模型上有所扩展,但是他描述了很多实现上细节,尤其是让GAN模型stable的方法。所以如果对于GAN的实现有兴趣,这篇文章也是必读。此外,最新NIPS2016也有最新的关于训练GAN模型的总结 [How to Train a GAN? Tips and tricks to make GANs work] (https://github.com/soumith/ganhacks“GAN tricks”)。 3、InfoGAN 在GAN模型中,生成模型的输入是一个连续的噪声信号,由于没有任何约束,即便我们得到一个有效的生成模型,z也不能被很好的解释。为了使输入包含可以解释,更有信息的意义,InfoGAN[7]的模型在z之外,又增加了一个输入c,称之为隐含输入(latent code),然后通过约束c与生成数据之间的关系,使得c里面可以包含某些语义特征(semantic feature),比如对MNIST数据,c可以是digit(0-9),倾斜度,笔画厚度等。具体做法是:首先我们确定需要表达几个特征以及这些特征的数据类型,比如是类别(categorical)还是连续数值,对每个特征我们用一个维度表示ci 。 接下来,利用互信息量来约束c。原理在于,如果 c 和生成的图像之间存在某种特定的对应(如果c是图像的某些特征,则有这样的函数存在),那么c和G(z,c)之间就应该有互信息量。如果是无约束的情况,比如z单独的每一个维度都跟和G(z)没有特定的关系,那么它们之间的互信息量应该接近0。所以加上这个约束之后,要优化的目标函数就变成了 min max V(D,G) = V(D,G) - ?? I(c;G(z,c)) (责任编辑:本港台直播) |