|
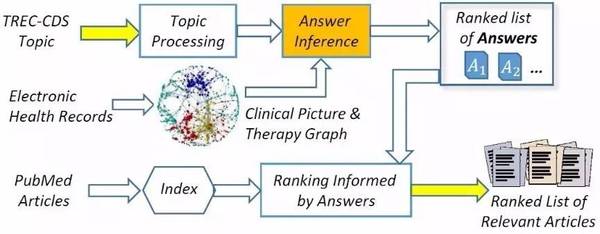
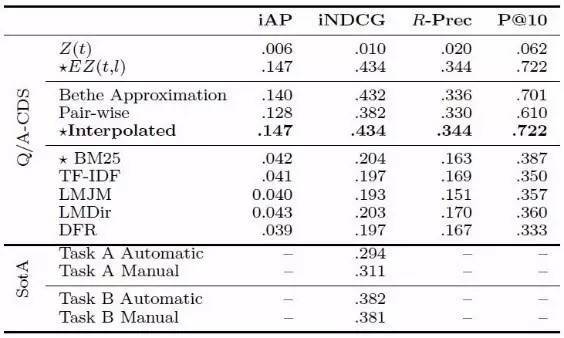
笔者上一篇文章主要对做了一个概括性描述,本次2016/1103/164877.html">CIKM会议研究领域总共录取了160篇长文,录取率为23%,109篇短文其中包括54篇扩充版短文(6页)和55篇短文(4页),录取率为24%。本文主要介绍几篇会议上值得留意的长文和短文。 ● 本次大会的最佳论文奖颁给了“ Vandalism Detection in Wikidata” (doi>10.1145/2983323.2983740)。 ● 最佳学生论文奖颁给了“Medical Question Answering for Clinical Decision Support” (doi>10.1145/2983323.2983819)和“Constructing Reliable Gradient Exploration for Online Learning to Rank” (doi>10.1145/2983323.2983774)两篇论文。 ● 最佳Demonstration奖颁给了“ Inferring Traffic Incident Start Time with Loop Sensor Data” (doi>10.1145/2983323.2983339) 。 下面着重介绍一下医疗问答的这篇文章。 “Medical Question Answering for Clinical Decision Support” 这篇论文属于自动问答系统研究范畴,该文章首先从大量电子医疗文档(EMRs)建立好一个非常大的概率性医疗知识图谱。知识图谱中节点的种类包括症状、诊断、测试以及治疗。然后根据知识图谱以及给定的医疗案例主题(包含该医疗案例的描述性片段,医疗案例总结,以及该医疗案例的问题),atv,该文章提出了三种生成答案的方法,最后用已生成的答案根据其与科学文献的相关度对科学文献进行排序,其整体框架以及实验结果如下图所示。之前解决该任务的方法基本上分为两步:1)根据每个主题的其他信息(描述性片段,医疗案例总结)对问题进行拓展;2)用已拓展的问题根据其与科学文献的相关度对科学文献进行排序。该文独特之处在于用知识图谱首先推理问题答案,再用答案代替问题直接和科学文献进行匹配。本任务最初的目的是希望找到对应的文献来回答每个主题的问题,所以用答案对文献进行排序的结果在理想状态下会优于用问题对文献进行排序的结果。研究医疗自动问答的读者可以仔细阅读一下全文。
在今年的2016/1103/164877.html">CIKM会议上,我们团队的一篇论文“Learning to Extract Conditional Knowledge for Question Answering using Dialogue”以长文的形式被录取。这是一篇关于条件性知识库搭建并用于驱动自动对话系统的文章。选题之初我们发现现实生活中很多人机对话往往是由于条件不足而引起的,比如在预订车票的对话中,常常会因为用户在发起订票命令时,缺少“时间”,“地点”,“人名”等条件,因此智能助手会主动提问,从而导致长对话的产生。相同的应用场景还有预定会议室、购买手机等场景。然而在目前的对话系统中,这些所谓的条件往往都是人工提前设定好的,只要系统检测到用户没有提供这个条件就会主动发问。然后每个场景的条件往往很不相同,这就会需要大量的人力来手动提取条件。 基于此,我们提出从问答语料库中自动抽取条件性知识库用以支撑人机对话。传统的知识库或知识图谱以三元组形式保存,即(主语,谓词,宾语)。本文提出的条件性知识库的形式为(主语,谓词,宾语|条件),其意义在于在给定主语和谓词不变前提下,宾语会根据条件的不同而不同,下图为我们运行实例框架图(图中假设选定windows 10为主语),抽取条件性知识库的整个框架主要由四部分组成: 模板挖掘(pattern mining)。这一步目的是从大量的问题答案对中抽取模板(pattern)。一开始我们项目处理的数据是整个开放的数据集,后来发现后续处理难度实在太大了。最后我们采取复杂问题简单化,先选取“how to”等简单句型进行处理,扩展到更多的句型乃至整个数据集是我们下一步的计划。 条件以及模板表示学习(condition and pattern representation learning)。这一步表示学习是为了给下一步聚类做准备。 条件以及模板聚类。一开始我们采用最简单的k-means方法聚类,但是发现结果非常不好,但是我们发现条件和模板共同出现的现象,最后我们提出一种新的基于表示的联合聚类(Embedding based Co-clustering)的方法聚类, 该方法融合了之前学习到的条件以及模板向量表示,同时在模板和条件两个角度上聚类。 (责任编辑:本港台直播) |