|
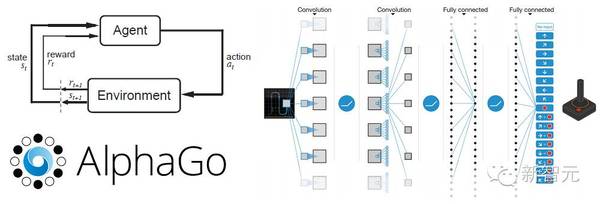
:COO、执行总编、主编、高级编译、主笔、运营总监、客户经理、咨询总监、行政助理等 9 大岗位全面开放。 简历投递:j[email protected] HR 微信:13552313024 新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。 加盟新智元,与人工智能业界领袖携手改变世界。 【新智元导读】机器学习技术总结回顾第二期:,本期关注的内容是强化学习。这本文中,作者从数学原理入手,深入分析强化学习。最后以深度强化学习著称的 DeepMind 两篇经典 Nature 论文为例,详解技术要领。推荐直接到作者博客看原文哦。
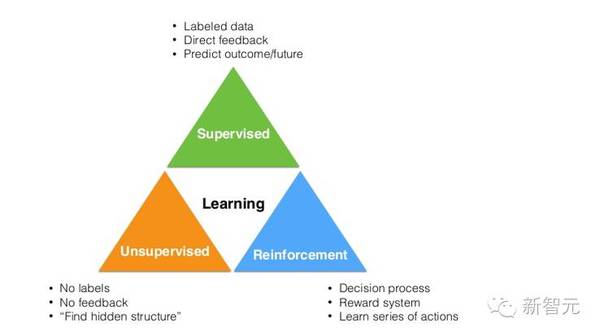
我们平均每周会推出新内容,对深度学习特定领域的研究论文进行汇总和说明。,本期关注的内容是强化学习。 进入正题之前,先了解一下什么是强化学习。机器学习有三个主要分类: 监督学习 无监督学习 强化学习
监督学习可能是大家最为熟悉的,其原理依据创建函数的方法或一组训练数据得出的模式,这些数据包含输入内容和相关标签。卷积神经网络就是一个很好的例子,输入的是图片,输出的是这些图片的分类。 无监督学习通过聚类分析的方法,找出数据内部的某种关系结构。典型的例子就要数最众所周知的ML聚类算法 K-means 算法。 强化学习主要研究在特定情境或环境下的操作方式,使得奖励信号最大化。强化学习与监督式学习之间有一个有趣的区别:强化学习的返回信号只能判断程序的操作(或输入)是好还是不好,而无法判断出哪一个程序操作是最好的。这与卷积神经网络不同,卷积神经网络程序里,每个图片的相应标签输入与输出都有设定好的指令。强化学习的另外一个独特之处在于,一个程序操作会影响其接收到的数据。比如,某个程序操作向左移动,而不是向右移动,意味着不同的操作中程序会接受到不同的输入信息。 正如上述所提到的,强化学习研究的是如何找出决策或操作的最优方案,以获得最大的奖励。奖励(Reward)是指一个回馈信号,显示操作在策略时间内是否执行得很好。程序每执行一个操作的行为(A)是指奖励(当前程序操作好或不好)和状态(S)的函数。状态是指程序所在的环境。对从环境状态到操作进行绘图叫做策略(P),策略基本上决定了特定时间内或特定情境下的操作方法。这样,我们就有了一个值函数(V),用来检测每个操作位置好在哪里。这跟奖励不一样,奖励是指直接感觉好的地方,而值函数是指它怎样好。最后还有一个模式(M),代表这个环境下的程序。程序模式指的就是程序在某个环境下的表现。
下面,我们先看一个例子。 马尔科夫过程(MDP) 我们首先需要想一下强化学习有哪些问题。假设有一个小型机器人,放在一个屋子里。如果不给这个机器人编写程序,使它移动、走动或执行其他操作,它就会一直待在那里,没有任何动作。这里机器人就是一个程序。 奖励函数由我们设定程序去完成什么任务来决定。比如说,让机器人移到屋子的角落,就可以获得奖励。机器人成功移到角落处,则加 25 分,每移动一步则减 1 分,程序设定目标是要让机器人以最快的速度移动到角落。程序操作可以向东、南、西、北四个方向移动。程序的策略很简单,程序操作总是向着目标位置移动,其值函数也会增加。很简单吧?获得高值函数的地方就是指这地方是好的(从长期奖励的角度讲)。 这样,整个强化环境就可以用马尔可夫决策过程(MDP)来表述了。如果有人从没听说过这个术语,简单的说,MDP 就是程序建立决策模型的框架。它包含一个有限的状态集(以及这么状态下的值函数)、一个有限行为集,策略以及奖励函数。值函数有两个主要的术语。 (责任编辑:本港台直播) |