|
不过,语音识别在一些特殊领域的识别效果就大打折扣了。在强干扰环境和特殊领域中,可以通过基于语音识别的关键词检索方法来进行音频信息的检查。 基于语音识别的关键词检索
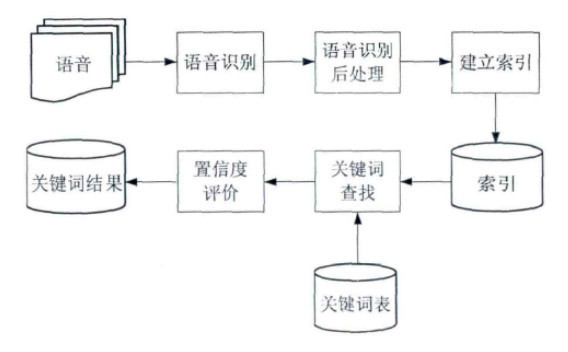
基于语音识别的关键词检索是将语音识别的结构构建成一个索引网络,然后把关键词从索引网络中找出来。从这一流程图中可以看到,首先把语音进行识别处理,从里面提取索引构建索引网络,进行关键词检索的时候,我们会把关键词表在网络中进行频率,找到概率最高的,输出其关键词匹配结果。 构建检索网络:
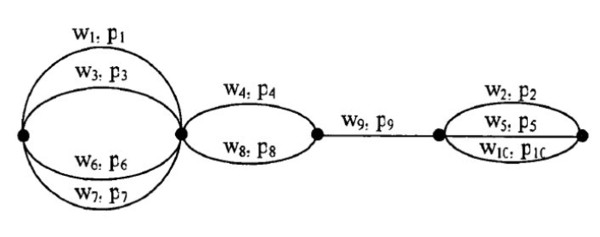
构建检索网络是语音关键词检索的重要环节。在这个图中,在第一个时间段内(w1、w3、w6、w7),这句话被识别成了四个不同的词,语音识别只能给出一条路径,但在语音关键词检索网络中可以从四个结果中进行筛选。 关键词检索:
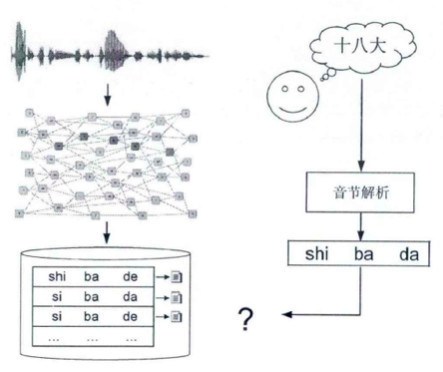
有了检索网络后,接下来的工作就是关键词检索工作。关键词检索是基于音节数据,首先将用户设定的关键词文本解析成音节数据,再从检索网络中找出匹配结果,相比语音识别这种文本结果检索,这种容错性更强,而且关键词检索可以只用在基于CTC,计算量更小,执行效率更高,更适用于海量数据的检索场景。 说话人识别的关键技术 说话人识别也称之为声纹识别,主要目的是对说话人的身份确认和辨识。
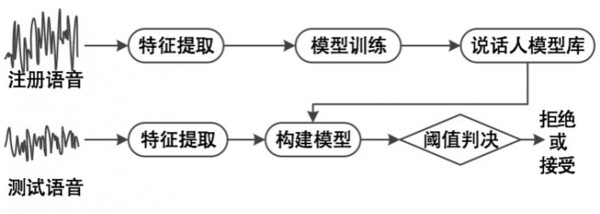
它的流程如下:首先对说话人的训练建模,把注册语音进行特征提取,模型训练之后得到说话人的模型库;在测试的时候,我们需要通过一个很短的音频去提取特征值,然后基于之前构建的模型进行阈值判断,判断出是集合内还是外,最终确认身份。 在这一过程中,注册语音只要10s左右的语音,测试只要2-5s的语音。 说话人识别的关键技术——特征提取-MFCC MFCC(梅尔频率倒谱系数),梅尔频率是基于人耳听觉特性提取出来的,和赫兹频率呈现一个非线性对应关系。梅尔频率倒谱系数是利用好梅尔频率和赫兹频谱关系计算得出的赫兹频谱特征,其主要应用于语音数据的特征提取。
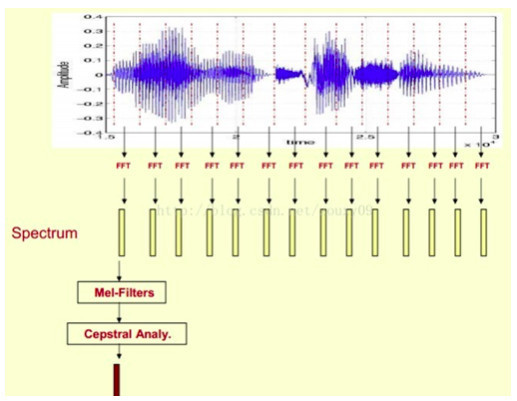
这张图显示的就是MFCC的提取过程,输入语音进行傅里叶变换,从中得到频谱,然后通过梅尔滤波器进行倒谱分析,再得到MFCC系数。 说话人识别的关键技术——特征提取-DBN MFCC是浅层的特征,只要通过语音参数的分析就可以得到,但是说话人之间不同的特征还体现在其它特点上,仅通过MFCC是无法捕捉到的。 所以又要利用神经网络来解决。神经网络有一个特征层叫BottleNeck,BottleNeck是深度神经网络参数维度最少的一层,很像一个瓶颈。 BottleNeck特征提取是通过语音识别深度神经网络训练得到的。 说话人识别的关键技术——模型训练GMM 完成关键特征提取后就要进行模型训练。
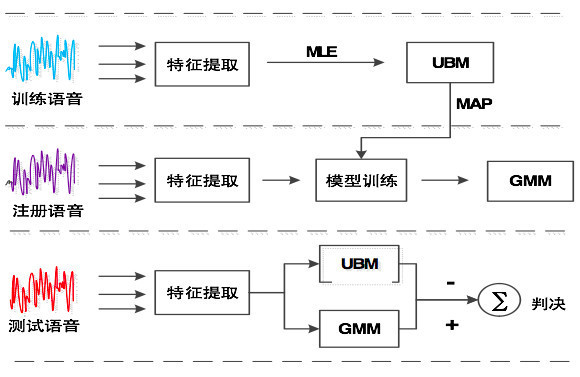
GMM的训练流程是:首先把训练语音进行特征提取,得到梅尔频率倒谱系数,然后生成一个通用背景模型,再通过MAP的方法得到说话人的模型。 注册语音的流程也是类似,通过特征提取,直播,进行模型训练得到混合高斯模型。 在测试的时候,把测试语音进行特征提取,然后从通用背景模型和混合高斯模型进行最大相似度的判断,再输出识别结果。 说话人识别的关键技术——模型训练I-Vector
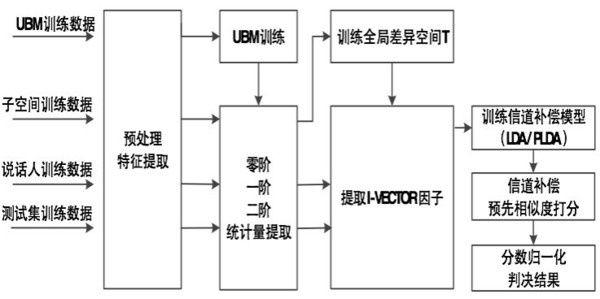
I-Vector在近两年有比较广泛的应用,它将说话人特征和信道特征统一建模,得到说话人特征通过信道补偿记录进行识别,有效解决了训练样本和实际检测样本存在信道不匹配的问题。 (责任编辑:本港台直播) |