|
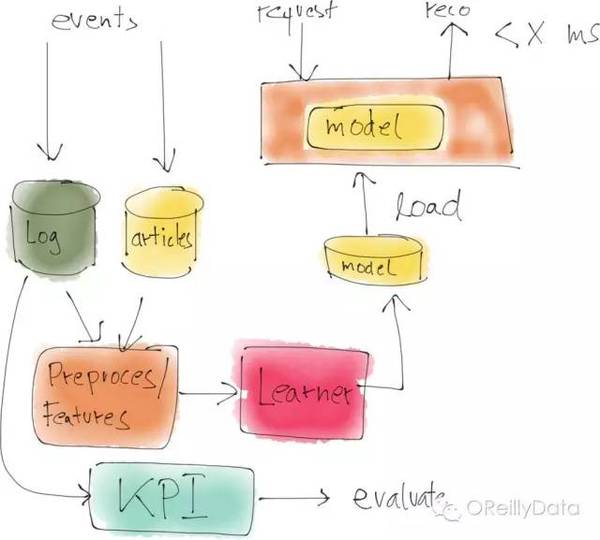
典型的数据科学工作流程(管道)如上图里所示:第一步总是从发现问题和收集一些数据(来自于数据库或者生产系统的日志)开始。取决于机构的数据准备好的程度,这一步有可能就是很困难的。首先,你有可能需要搞清楚谁能让你接触到所需的数据,并搞清楚谁能给你权限去使用这个数据。当数据可用后,它们就可能需要被再次处理,以便提取特征值。你希望这些特征可以为解决问题提供有用的信息。接着,这些特征值被导入学习的算法,并用测试数据对产生的结果模型做评估,以决定这个模型是否能较好地对新数据做预测。 上述的这个分析管道通常都是短期一次性的工作。一般是由数据科学家手工完成所有的步骤。数据科学家可能会用到如Python这样的编程语言,并包括很多的数据分析和可视化的库。取决于数据数量,有时候数据科学家也使用类似Spark和Hadoop这样的计算框架。但一般他们在一开始都只会使用整个数据集的一小部分来做分析。 为什么开始只用一小部分数据 开始只用一小部分数据的主要原因是:整个分析管道过程并不是一锤子买卖,而是非常多次反复迭代的过程。数据科学项目从本质上讲是探索性的,甚至在某种程度上是开放式的命题。虽然项目目标很清楚,但什么数据可用,或可用的数据是否适合分析,这些在项目一开始都不是很清楚。毕竟,选择机器学习作为方法就已经意味着不能仅仅只是通过写代码来解决问题。而是要诉诸于数据驱动的方法。 这些特点都意味着上述的分析管道是迭代的,并需要有多次改进,尝试不同的特征、不同的预处理模式、不同的学习方法,甚至是重回起点并寻找和实验更多的数据来源。 这整个过程本质上就是反复的,而且经常是高度探索性的。当做出的模型的整体的表现不错后,数据科学家就会对真实的数据运用开发的分析管道。到这时,我们就会面临与生成系统的集成问题。
图4:图片来自Mikio Braun的演讲页 区分生产系统和数据科学系统 生产系统和一个数据科学系统的最主要区别就是生产系统是一个实时地、在持续运行的系统。数据一定要被处理而模型必须是经常更新的。产生的事件也通常会被用来计算关键业务性能指标,atv,比如点击率等。而模型则通常会每隔几个小时就被用新数据再进行训练,然后再导入生产系统中去服务于新来的(例如通过REST接口送入的)数据。 这些生产系统一般都是用如Java这样的编程语言写的,可以支持高性能和高可靠性。
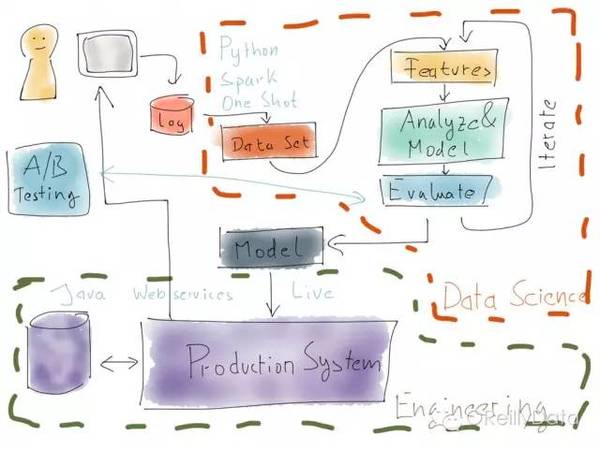
图5:图片来自Mikio Braun的演讲页 如果你把生产系统和数据科学系统并排放置,那么就会得到一个类似上图的情况。在右上角,是数据科学的部分。其典型特征是使用类似Python的语音或者是Spark的系统,但一般是一次性的手工触发的计算任务,并经过迭代来优化整个系统。它的产出就是一个模型,本质上就是一堆学习到的数字。这个模型随后被导入进生成系统。而生产系统则是一个典型的企业应用系统,用诸如Java语言写成的,并持续运行。 当然,上面的这个图有一些简化了。现实中,模型都是需要被重新训练的,所以一些版本的数据处理管道会和生成系统集成在一起,以便不时地更新生产系统里的模型。 请注意那个在生成系统里运行的A/B测试。它对应于数据科学一侧的评估部分。但这两部分经常并不完全具有可比性。例如不把离线的推荐结果展示给客户,就很难去模拟一个推荐的效果,但有这样做可能会带来性能的提升。 最后,必须要意识到,这个系统并不是在安装部署完成后就“万事大吉了”。就如数据科学侧的人需要迭代多次来优化数据分析管道,整个实时系统也必须随着数据分布漂移来做迭代演进。由此新的数据分析任务就成为可能。对我而言,能正确做好这个“外部迭代”是对生产系统的最大的挑战,同时也是最重要的一步。因为这将决定你能否持续地改善生产系统,并确保你在数据科学上的初期投资取得回报。 数据科学家和程序员:合作的模式 (责任编辑:本港台直播) |