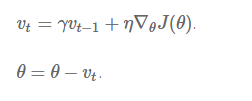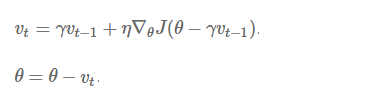|
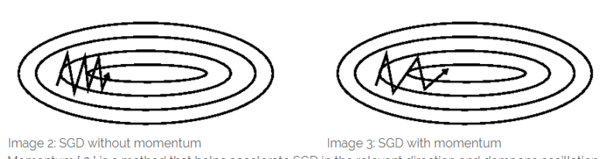
选择适当的学习率是一个难题。太小的学习率会导致较慢的收敛速度,而太大的学习率则会阻碍收敛,并会引起罚函数在最小值处震荡,甚至有可能导致结果发散; 我们可以设置一个关于学习率地列表,通过如退火的方法,在学习过程中调整学习率——按照一个预先定义的列表、或是当每次迭代中目标函数的变化小于一定阈值时来降低学习率。但这些列表或阈值,需要根据数据集地特性,被提前定义。 此外,我们对所有的参数都采用了相同的学习率。但如果我们的数据比较稀疏,同时特征有着不同的出现频率,那么我们不希望以相同的学习率来更新这些变量,我们希望对较少出现的特征有更大的学习率。 在对神经网络最优化非凸的罚函数时,另一个通常面临的挑战,是如何避免目标函数被困在无数的局部最小值中,以导致的未完全优化的情况。Dauphin 及其他人 [19] 认为,这个困难并不来自于局部最小值,而是来自于「鞍点」,也就是在一个方向上斜率是正的、在一个方向上斜率是负的点。这些鞍点通常由一些函数值相同的面环绕,它们在各个方向的梯度值都为 0,所以 SGD 很难从这些鞍点中脱开。 梯度下降的优化算法 在如下的讨论中,我们将会列举一些应对上述问题的算法,它们被广泛应用于深度学习社区。同时,我们不会讨论那些不能应用于高维数据集的方法,例如牛顿法等针对二阶问题的方法。 动量法 SGD 很难在陡谷——一种在一个方向的弯曲程度远大于其他方向的表面弯曲情况——中找到正确更新方向。而这种陡谷,经常在局部极值中出现。在这种情况下,如图 2 所示,SGD 在陡谷的周围震荡,向局部极值处缓慢地前进。
动量法 [2],如图 3 所示,则帮助 SGD 在相关方向加速前进,并减少它的震荡。他通过修改公式中,在原有项前增加一个折损系数γ,来实现这样的功能:
注意:在其他的一些算法实现中,公式中的符号也许有所不同。动量项 γ 往往被设置为 0.9 或为其他差不多的值。 从本质上说,动量法,就仿佛我们从高坡上推下一个球,小球在向下滚动的过程中积累了动量,在途中他变得越来越快(直到它达到了峰值速度,如果有空气阻力的话,γ<1)。在我们的算法中,相同的事情发生在我们的参数更新上:动量项在梯度指向方向相同的方向逐渐增大,对梯度指向改变的方向逐渐减小。由此,我们得到了更快的收敛速度以及减弱的震荡。 Nesterov 加速梯度法 但当一个小球从山谷上滚下的时候,盲目的沿着斜率方向前行,其效果并不令人满意。我们需要有一个更「聪明」的小球,它能够知道它再往哪里前行,并在知道斜率再度上升的时候减速。 Nesterov 加速梯度法(NAG)是一种能给予梯度项上述「预测」功能的方法。我们知道,我们使用动量项γvt-1 来「移动」参数项θ。通过计算θ-γvt-1,我们能够得到一个下次参数位置的近似值——也就是能告诉我们参数大致会变为多少。那么,通过基于未来参数的近似值而非当前的参数值计算相得应罚函数 J(θ-γvt-1) 并求偏导数,我们能让优化器高效地「前进」并收敛:
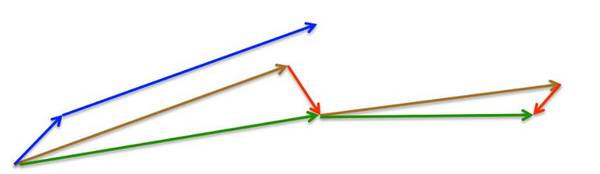
在该情况下,我们依然设定动量系数γ 在 0.9 左右。如下图 4 所示,动量法首先计算当前的梯度值(小蓝色向量),然后在更新的积累向量(大蓝色向量)方向前进一大步。但 NAG 法则首先(试探性地)在之前积累的梯度方向(棕色向量)前进一大步,再根据当前地情况修正,以得到最终的前进方向(绿色向量)。这种基于预测的更新方法,使我们避免过快地前进,并提高了算法地响应能力(responsiveness),大大改进了 RNN 在一些任务上的表现 [8]。
--image4: Nesterov Update 法,来源:G. Hinton's lecture 6c-- 参考这里,以查看 Ilya Sutskever 在它博士论文中,对 NAG 机理的更为详尽的解释 [9]。 (责任编辑:本港台直播) |