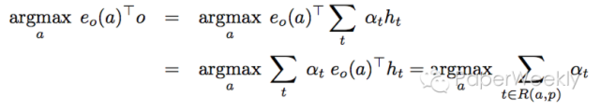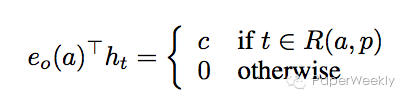|
PaperWeekly已经介绍过不少Question Answering的相关工作。主要有DeepMind Attentive Reader,FAIR Memory Networks,Danqi’s Stanford Reader, Attention Sum Reader, Gated Attention Sum Reader, Attention Over Attention Reader, etc. 这些模型关联性很大,或多或少存在相似之处。本文给大家介绍一下Toyota Technological Institute at Chicago (TTIC)在Question Answering方面的相关工作,共有3篇paper: 1、Who did What: A Large-Scale Person-Centered Cloze Dataset, 2016 2、Broad Context Language Modeling as Reading Comprehension, 2016 3、Emergent Logical Structure in Vector Representations of Neural Readers, 2016 Who did What: A Large-Scale Person-Centered Cloze Dataset作者 Takeshi Onishi, Hai Wang, Mohit Bansal, Kevin Gimpel, David McAllester 文章来源 EMNLP 2016 问题 文章构建了一个新的Question Answering dataset,”Who did What”。 sample instance如下图所示。
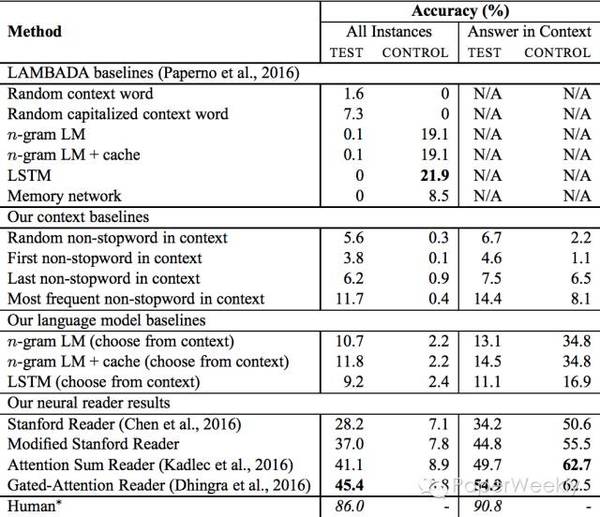
问题的句子总是挖掉了一些named entities,然后给出在文中出现过的别的named entities作为选项。这一个dataset的难度要高于之前的CNN/DM dataset,可以作为创建新模型的参考数据集。 模型 构建此数据集的方法与CNN/DM不同,问题并不是context passge的一个summary。问题与context均来自Gigaword Corpus,他们是两篇非常相关的文章。 具体来说,atv,我们先找到一篇文章,作为question文章。然后提取出文中第一句话的named entities,删除其中的一个named entity作为将要被预测的答案。然后利用这一句question sentence,我们可以利用一些Information Retrieval系统从Gigaword Corpus找到一篇相关的文章作为passage。这篇文章与question文章不同,但是包含着与question sentence非常类似的信息。 有了passage之后,我们再从passage中找出named entities作为candidate answers。 为了使任务难度更大,我们用一些简单的baseline (First person in passage, etc) 将一些很容易做出的问题删掉,只留下比较困难的instances。这样构建的数据比CNN/DM会困难不少。 简评 相信作者创建的新数据集会给Machine comprehension带来一些新的问题与挑战,是很有价值的资源。文章采用的baseline suppresion方法可以用比较小的代价加大问题的难度,值得参考。 Broad Context Language Modeling as Reading Comprehension作者 Zewei Chu, Hai Wang, Kevin Gimpel, David McAllester 文章来源 arXiv 问题 不久前发布的LAMBADA dataset中,作者尝试的各种baseline models都给出了比较差的结果。 每一个LAMBADA instance如下图所示。
模型 在观察了LAMBADA dataset之后,我们认为可以利用Reading comprehension models来提升准确率,而不必使用传统的language model。 由于state of the art reading comprehension models需要给出candidate answers,然后从中选出一个作为预测的答案,我们就将所有在context中出现过的单词都作为一个candidate answer。 LAMBADA给出的训练集是一些小说的文本。为了使训练集与测试集的数据类型保持一致,我们构建了一个biased training set。具体的做法是,我们将training set划分成4-5句话的context,然后保证target word在context passage中出现,只保留这样的训练数据。我们在新构建的training set上训练各种attention based models,得到了比原作者好得多的测试结果。
简评 这篇文章中,作者利用了简单的方法和模型将LAMBADA dataset的准确率从7.3%提高到45.4%,非常简单有效。 Emergent Logical Structure in Vector Representations of Neural Readers作者 Hai Wang, Takeshi Onishi, Kevin Gimpel, David McAllester 文章来源 ICLR 2017 Submission 问题 最近提出的各种各样的attention based reader models,本文作者做了一个比较全面的总结和分析,并且通过数学分析和实验展示了模型之间的相关性。 模型 本文作者认为,当前的attention based models可以分为两类,atv,aggregation readers(包括attentive readers和stanford readers)以及explicit reference readers(包括attention sum reader和gated attention sum reader)。 这两种reader可以用如下的公式联系在一起。
要满足上述等式,只需要满足下面的公式。
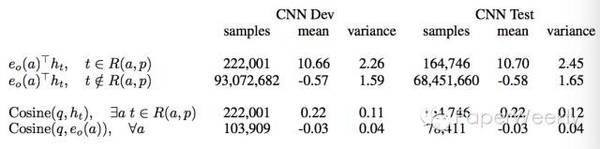
也就是说,只有正确答案所在的hidden vector和question vector得到的inner product才能给出不为零的常数。以下实验结论支持了这一假设。
|