|
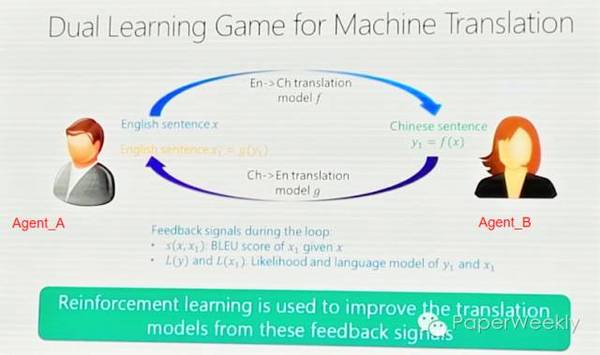
Wildcard denoising的目的是缓解overfitting,做法是随机选择一些词,替换成,而不是直接扔掉词,实验验证准确率会提成20%左右。Beta-pooling的目的是将向量序列pool成固定长度为2K_W的单向量,帮助rating matrix的矩阵分解;因为不同序列可能需要不同大小的权重,所以需要变长的beta向量来帮助pooling,文章采用beta分布。 Learning的过程采用MAP,类似于CDL和DTR。学到矩阵U和V之后,我们可以预计评分矩阵R。 资源 1、CiteULike 2、Netflix 相关工作 选取当中两个比较有意思的work。 1、CTR (collaborative topic reguression) 将topic model和probabilistic matrix factorization (PMF),但是CTR采用bag-of-words的表示形式,忽略了词序和每个词的局部语境,而这些对文章表示和word embeddings能提供有价值的信息。 2、CDL (collaborative deep learning) 将CF和probabilistic stacked denoising autoencoder (SDAE)结合起来,是一个以bag-of-words为输入的feedforward模型,并不能解决sequence generation的问题。 简评 这篇文章将RNN用于recommendation,并且与rating matrix结合起来,比较有意思,而且考虑了数据稀疏的情况,pooling的方法也值得借鉴。 Dual Learning for Machine Translation作者 Yingce Xia1, Di He, Tao Qin, Liwei Wang, Nenghai Yu1, Tie-Yan Liu, Wei-Ying Ma 单位 1、University of Science and Technology of China 2、Key Laboratory of Machine Perception (MOE), School of EECS, Peking University 3、Microsoft Research 关键词 Dual Learning, Machine Translation, Deep Reinforcement Learning 文章来源 arXiv, 1 Nov 2016 问题 文章针对机器翻译时需要的人工标注的双语平行语料获取代价高的问题,提出了Dual Learning Model使用单语语料来进行训练,j2直播,取得了比使用双语平行语料训练的模型更好的结果。 模型 模型的核心思想见下图:
注:上图来自CCL2016马维英老师PPT 对上图的详细解释: 模型中有两个Agent,Agengt_A和Agent_B,Agent_A只能够理解A语言,Agent_B只能理解B语言,model f是将A语言翻译成B语言的翻译模型,model f是将B语言翻译成A语言的翻译模型。上图的执行过程可以按照下面的解释进行: 1、Agent_A 发送一句A语言的自然语言的话X1 2、model f将X转换成为B语言的自然语言Y 3、Agent_B收到Y,并将Y 传送给model g 4、model g将Y转换成源语言A的自然语言X2 5、比较X1和X2的差异性,并给出反馈.并进行1到4的反复训练 模型的算法过程:
在step8的时候对翻译模型翻译的结果使用语言模型做了一个判定,判定一个句子在多大程度上是自然语言。step9是给communication一个reward,step10将step8和step9加权共同作为样例的reward.然后使用policy gradient进行优化。 需要说明的model f和model g是已有的模型或者说在刚开始的时候使用少量的双语语料进行训练得到吗,然后逐渐加大单语语料的比例。 资源 1、NMT code:https://github.com/nyu-dl 2、compute BLEU score by the multi-bleu.perl:https://github.com/moses-smt/mosesdecoder/blob/master/s/generic/multi-bleu.perl 相关工作 1、the standard NMT, Neural machine translation by jointly learning to align and translate. ICLR, 2015. 2、pseudo-NMT, Improving neural machine translation models with monolingual data. In ACL, 2016. 简评 (责任编辑:本港台直播) |