|
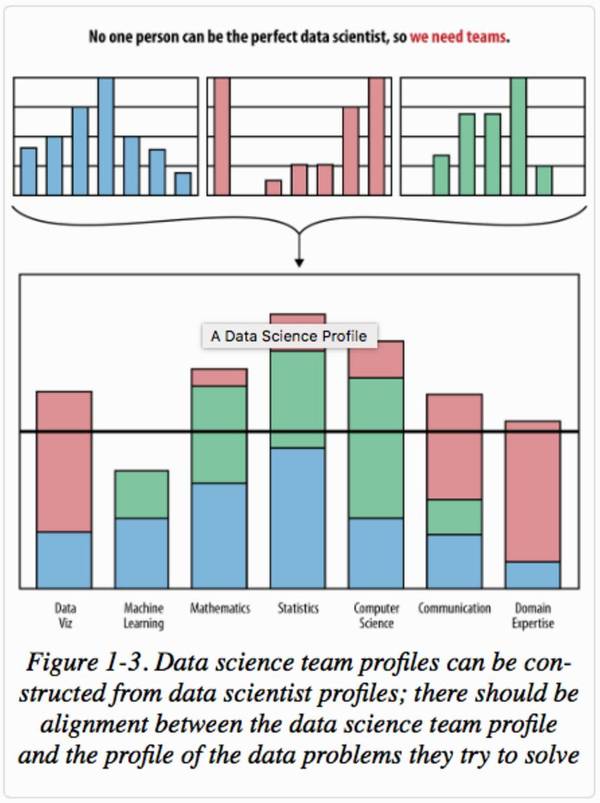
参与:杜夏德、李泽南、蒋思源、吴攀 昨日机器之心编译的一篇文章(参见:)显示Python已经逐渐成为最受欢迎的机器学习语言。在今日的 Quora 专题上, 《Python机器学习》一书的作者 Sebastian Raschka 回答了有关 Python、机器学习、计算生物学方面的许多问题。让我们通过这个专题看看这个机器学习界的明星(他被列为Github中最有影响力的数据科学家之一)是如何完成从生物到计算机的传奇跨界经历的。 1. 你用过什么让你工作效率提升的工具? 从较高的层面来说,我把「计算编程语言和算法」视为最重要的生产工具,它能处理所有类型的问题。然而,从软件应用层面来说,我喜欢 Atom Editor(我仍在使用 VIM 进行远程工作)。每天我都需要编写很多不同类型的文件:Python 脚本、.cpp 文件、HTML 文件、Markdown、.tex 、纯文本文件、蛋白质结构文件等等。Atom Editor 支持跨平台(macOS 和 Linux)并带有丰富的插件系统。自从有了 VIM 后,我逐渐习惯使用这个小工具了。当然,我的大部分数据分析工作都在 Jupyter Notebook 上做。我不会用 Jupyter 来「开发」代码,但是对我来说,它为我提供一个记录研究轨迹的环境,就像一本「笔记本」,把所有的事情都集中在一处:执行代码,不同的 notation 和 comment,inline plots,以及 LaTeX 等式,不仅节约了时间,在我回顾某个项目写报告赶 deadline 时,它还是我的救命武器,哈哈。 对了,差点忘了「git」(和 GitHub)和一个强大的笔记类应用程序 Quiver(只能在 Mac 上用)。笔记类应用太多了,但我只喜欢 Quiver,它能输出所有格式的数据,有了它你永远不会觉得你会陷入某个特定的程序或格式。 2. 对一个刚入行的、有点手忙脚乱的机器学习/数据科学家,你有什么建议? 我认为手上握有太多的可用资源既有好处又有坏处。好的是我们有很多可选的工具和信息资源,但是为了利用好时间充分使用它们,做好「选择」和保持「关注」才是真正重要的事情。 我不想说很多资源都是「冗余的」,因为「冗余」这个词用在这里有点负面。然而,市面上有很多看似不同的书、工具、教程,内容实际上都差不多,可能在范围和风格上有些差别。 所以,不要想贪多,我们总是被长长的阅读清单拖后腿,更重要的是先想清楚个人的目标(「我需要学习那些技能来解决 X 问题?」「我真的要学这个流行的 X 工具而不是 Y 工具吗?」)。资料和工具太多了,我们需要更加精心地挑选。当然有时候我们会感觉是不是错过了什么,但是我觉得习惯这种感觉会帮你把注意力集中在某一件事情上,取得稳定的进步。 例如,我认为「机器学习简介」的书一本就足够了,没必要每本都读,除非你真的感觉到内容不完整需要补充。就像 Cathy O'Neil 和 Rachel Schutt 解释的那样,没有「完美」的数据科学家,因为没有时间去学每样东西。每个人掌握属于自己的一套技能,擅长某一领域就可以了。 我认为不知道所有的事情不一定是件坏事。因为(如下图所示)我们能通过团队合作来弥补各自的缺陷。
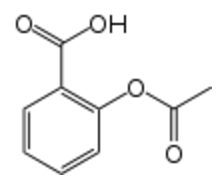
3.2016 年机器学习领域发生的哪件事让你最兴奋? 我对如何将解决特定问题的技术比如卷积神经网络和循环神经网络应用到除图像识别和神经语言处理外的其他问题上极度感兴趣。我认为现在这些技术应用上的一个关键挑战是找到合适的「表征」(除了有足够的 数据外)。这里有个例子(比较旧), Lusci, Alessandro, Gianluca Pollastri, 和 Pierre Baldi。「化学信息学中的深度架构和深度学习:药物类分子的水溶性预测」Journal of chemical information and modeling 53.7(2013):1563-1575. 研究者们用有向非循环图呈现分子(通常来说,结构是无向循环图)作为递归神经网络的输入,来预测这些分子的水溶性。 最近的一个例子是:Gómez-Bombarelli, Rafael 等人「使用数据驱动的连续分子表达进行自动化学设计(Automatic chemical design using a data-driven continuous representation of molecules)」arXiv:https://arxiv.org/abs/1610.02415 简而言之,研究者们训练了一个自动解码器来生成现实的、合成分子。这里,他们的神经网络将 SMILES 串转换成潜在的表达(经过压缩后仅包含统计上的显著信息的向量)并以最小的(或者没有)误差回到 SMILE 串。SMILE 串是一个分子的一维表达;例如,阿司匹林的 SMILES 串是 CC(=O)OC1=CC=CC=C1C(=O)O 对应的是下面的二维结构:
阿司匹林(2 -(乙酰氧基)苯甲酸) (责任编辑:本港台直播) |