|
编译:李静怡、王楠 :COO、执行总编、主编、高级编译、主笔、运营总监、客户经理、咨询总监、行政助理等 9 大岗位全面开放。 简历投递:j[email protected] HR 微信:13552313024 新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。 加盟新智元,与人工智能业界领袖携手改变世界。 【新智元导读】Samy Bengio,的弟弟,昨天在 Arxiv 上发布了他与同事、Google Brain 研究人员 Lukasz Kais被今年 NISP 接收的文章,提出了一种新的模型,提升神经机器翻译水平,同时解开了 Active Memory 为何在提升机器翻译的效果不如提升语音、图像识别的原因,最后介绍了如何发挥 Active Memory 模型的最大潜力,以及哪些情况下更适合使用注意力模型。【进入新元微信公众号,直播,在对话框输入“1029”下载谷歌大脑最新 NIPS 论文】 此前,atv,新智元曾经报道了,神经网络机器翻译(NMT) 是一种用于自动翻译的端到端学习方法,有很大的潜力可以克服传统基于词组的翻译系统的缺点。遗憾的是,不管是在训练还是在翻译推理上,NMT系统的计算成本是出了名的高,有时候在大型的数据集或者大的模型上成本更是高得离谱。也有一些作者指出,NMT 系统缺乏鲁棒性,尤其是当输入的句子包含很少的单词的情况下。这些问题的存在,阻碍了NMT在实际的部署和服务中的应用,因为实际应用中,准确率和速度都是至关重要的。 为此,谷歌提出了 GNMT(谷歌神经机器翻译系统)尝试解决以上难题。我们的模型包括了一个深度的 LSTM 网络,从解码网络到编码网络中,既使用残差连接,也使用注意力连接。为了提升并行计算进而减少训练时间,当时,谷歌团队将注意力机制把底层的解码器与顶层的编码器连接起来,同时为了加速最后的翻译速度,他们在推理计算的过程中采用了低精度的算法。 现在,虽然还没有投入实际应用,谷歌大脑团队的研究人员 Lukasz Kaiser、Samy Bengio 通用提出一个新的模型,进一步改善了神经网络机器翻译,不仅如此,在其他领域这个模型也能够提升性能。 全新 Active Memory 延伸模型,提升机器翻译水平
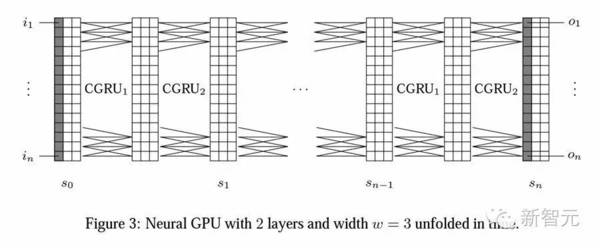
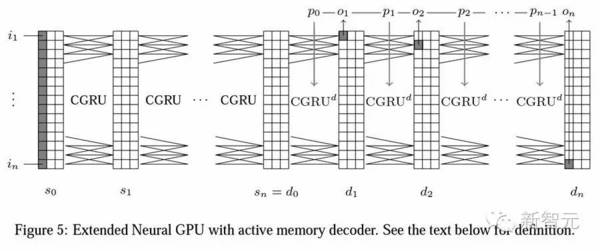
论文作者使用大量“Active Memory”这一术语,指的是在模型中,记忆网络的每一部分在每个步骤中都会产生主动的变化。这跟注意力模型产生了明显的对比。在注意力中,每一步骤只有一小部分的记忆会改变。在注意力模型中,记忆一般都维持不变。不同模型间,记忆的主动变化可能会有所不同。在本论文中,作者聚焦于这一改变最常见的方式,它们全部依赖于卷积算子(convolution operator)。 卷积在 kernel bank 和3D 向量上起作用。另外,本研究中使用的 kernel bank 适配于许多常见的深度学习工具包中的标准卷积算子。使用标准的算子,是因为它可以在优化上非常好,并且在卷积的优化上,能直接从任何新的研究获得帮助。以记忆向量为例,一个主动的记忆模型通过使用一系列的卷积,并把这些卷积相结合,创造出下一个记忆。虽然残差模型在图像分析和生成上获得了巨大的成功,它们可能会遭遇梯度消失的难题,这与递归神经网络所面临的是一样的。 Active Memory 模型为何不适用于提升 NLP 注意力
为了更好地理解此前 Active Memory 模型的主要缺陷,论文作者比较了不同注意力模型 log-perplexity 平均值,发现单纯的 Neural GPU 模型得出的结果是 3.5,使用了马尔科夫方法的是 2.5,只有完全依赖、使用 teacher forcing 训练的模型达到了 1.3。递归依赖生成输出分布的关键原来才是达到良好性能的关键。 由此表明,输出分布中的依赖性问题可以从模型或模型类的特殊性中解开。在早先的研究中,这种依赖(和 teacher forcing 训练)总是在 LSTM 和 GRU 模型中使用,但在其他种类模型中很少使用。因此,作者认为从模型架构中单独考虑这个问题可能是有益的。 特定情况下,Active Memory 模型甚至能超过注意力模型 扩展神经GPU 的这种思维方式可能对其他类型的模型也有用。 在解决递归输出分布问题时,Active Memory 模型在解决大规模真实世界问题的时候效果完全可以等同甚至超过注意力模型。 那么,用 Active Memory 就可以替代注意力模型了吗? 在 soft attention 的情况下,答案可以是肯定的。 不过,作者表示,注意力 mask 是一个非常自然的概念,在集中解决单个问题时能更加有用,尤其是在 hard attention 方面。 Google Brain NIPS 论文:Active Memory 能取代注意力吗?
摘要 (责任编辑:本港台直播) |