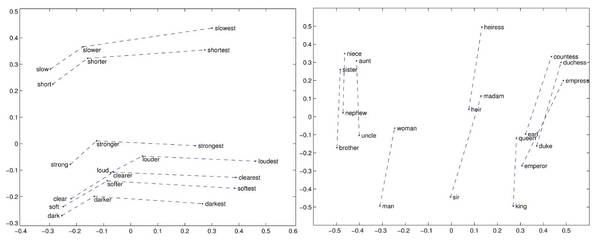
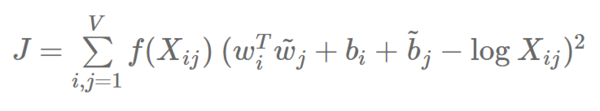|
全局矢量(GloVe) 词嵌入量与分布式语义模型 模型 超参数 结果 请原谅之前的噱头。这是一篇我很久之前就想要去写的博客。在这篇文章中,我想要强调那些使得 word2vec 成功的秘密成分。 我特别要专注于通过神经模型训练的词嵌入与通过传统的分布式语义模型(DSMs)产生的词嵌入之间的联系。通过展示这些组分是如何被转移到 DSMs 中的,我将会证明分布式的方法是丝毫不逊色于流行的词嵌入方法的。 虽然没有什么新的见解,但我感觉传统的方法经常被深度学习的热潮所掩盖,它们之间的相关性应该受到更多关注。 因此,这篇博客所依据的文献是 Levy 等人在 2015 年发表的通过词嵌入获得的提升分布式相似性的研究。如果你还没有阅读过,我建议你抓紧搜索。 在这篇公开的博客中,我将首先介绍一个流行的词嵌入模型 GloVe,然后我将突出词嵌入模型和分布式予语义方法之间的联系。 紧接着,我将会介绍用来衡量不同因素影响的四款模型。之后我会给出除了算法选择之外其他学习词表示中额外因素的概述。最终我将呈现 Levy 等人的建议和结论。 全局矢量(GloVe) 在之前发布的那篇博客中,我们已经对流行的词嵌入模型进行了概述。我们遗漏的一个模型便是 GloVe。 简而言之,GloVe 希望能明确表明 SNGS 的隐式操作:编码含义作为嵌入空间中的向量偏移——看起来只是一个偶然发现的 word2vec 的副产品——才是 GloVe 的特定目标。 具体来说,GloVe 的作者表明两个词同现概率的比值(而不是它们的同现概率本身)是包含信息并计划作为向量差来编码信息。 为了实现这一目标,他们提出了一种加权最小二乘法的物体 J,旨在最小化两个词的向量点积与它们共现次数的对数之间的差异。
当 wi 和 bi 分别作为词语 i 的词向量和偏差,w~j 和 bj 分别作为词语 j 的文本词向量和偏差,Xij 是在词语 j 的文本中出现词语 i 的次数,而 f 是将相对低的权重分配给稀有和频繁共现的加权函数。 共现次数可以被直接编码到词语上下文的共现矩阵中,GloVe 会将这样的矩阵而不是整个语料库作为输入。 如果你想更多地了解 GloVe,最好的参考便是相关的论文或者附属网站 ()。除此之外,通过 Gensim 的作者,Quora 问答(https://www.quora.com/How-is-GloVe-different-from-word2vec)或是这篇发布的博客 (https://cran.r-project.org/web/packages/text2vec/vignettes/glove.html),你可以对 GloVe 及其与 word2vec 的差异有更多的了解。 词嵌入与分布式语义模型 词嵌入模型,尤其是 word2vec 和 GloVe 变得如此流行的原因是它们的表现似乎一直以来都显著优于 DSMs。许多人将此归因于 Word2vec 的神经架构或是它能预测词语这个事实,这看起来要比只靠共现计数有天然的优势。 我们可以将 DSMs 看做计数模型,因为它们通过操作共现矩阵来计算词语的共现次数。相反,神经词嵌入模型可以被看作是一种预测模型,因为它们会去预测周围的词语。 2014 年,Baroni 等人表明预测模型几乎在所有的任务中都优于计数模型,从而为词嵌入模型显而易见的优越性提供了一个清晰的证明。这就是终点了吗?并不是。 我们已经看到和 GloVe 的差异并不是那么明显:当 GloVe 被 Levy 等人认为是一个预测模型时,它显然是正在分解一个词语上下文共现矩阵,这使其更接近于诸如主成分分析(PCA)和潜在语义分析(LSA)等传统的方法。不止如此,Levy 等人还表示 word2vec 隐晦地分解了词语上下文的 PMI 矩阵。 所以,虽然在表面上 DSM 和词嵌入模型使用不同的算法来学习词语表示——前者计数,后者预测——但从根本上来说,两种类型的模型表现了相同的底层数据统计,即词语间的共现次数。 因此,仍然存在同时也是这篇博客剩下的部分想要回答的一个问题是: 为什么词嵌入模型的表现仍然比几乎拥有相同信息的 DSM 更好? 模型 (责任编辑:本港台直播) |