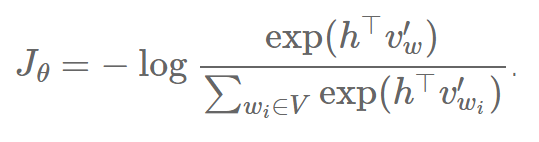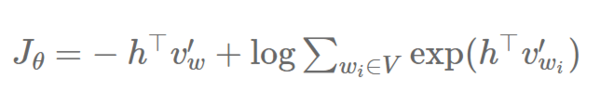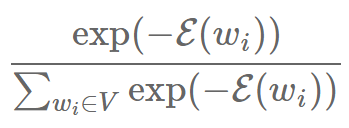|
研究者也强调不需要用 CNN-softmax,而是把前一层h的输出传入一个字母层次的 LSTM,它输出词语的方式可以是一次输出一个字母。因此,每一个时间步中,softmax 输出的并不是词,而是字母的概率分布。然而,他们不能得到和这一层相当的表现效果。Ling 等人[14] 为机器翻译采用一个相似的层,得到了具有竞争力的效果。 基于采样的方法 上文中讨论的这些方法仍然保持着 softmax 大体的结构,而基于采样的方法则完全和 softmax 层无关。它们的方式是近似其它的损失函数的 softmax 的分母的正则化来。然而,基于采样的方法只是在训练时有效——在推断(inference)中,完全的 softmax 仍然需要计算来获得一个正则化后的概率。 为了直观上看 softmax 分母在损失函数的影响,我们将会推导我们相对于我们模型 θ 的损失函数 Jθ 的梯度。 在训练过程中,我们希望给训练集中的每个词 w 减少模型的交叉熵损失函数(cross-entropy loss)。这就是我们的 softmax 的输出的负对数。如果您不确定 softmax 和 cross-entropy 的关系,请看看Karpathy的解释 (#softmax-classifier)。我们的损失函数如下:
请注意在实际操作中,Jθ 就是在整个数据集的所有负对数概率的平均值。为了获得这个推导,我们可以把 Jθ 分解成 :
的和:
为了简洁,并且和 Bengio 和 Senécal [4 , 15]的标号对应起来(注意到第一篇文章中,他们计算了正对数的梯度),我们用 ?E(w) 来代替 h?v′w 的点积。我们的损失函数于是看起来像这个形式:
为了反向传播,我们现在可以计算相对于我们的模型参数 θ 的 Jθ 的梯度 ?:
因为 logx 的梯度是1x,运用链式法则可得:
我们现在可以在和中移动梯度:
因为 exp(x) 的梯度就是 exp(x),再一次运用链式法则可得:
我们可以把它写成:
注意到:
只是 wi 的 softmax 概率 P(wi)(为了简洁,我们忽略它对上下文 c 的依赖)。替换它,我们得到:
最后,重新把负系数放到和前面,可得:
Bengio和Senécal(2003)发现了梯度最终由两部分组成:一个是给目标词 w 的正反馈(上一个式子中的第一项),一个是给其它词 wi 的负反馈,由它们的概率 w(第二项)反映出来。我们可以发现,这个负反馈只是对于所有V中的词 wi 的梯度 E 的
的期望:
现在大多数的基于采样方法的难点是去近似负反馈,让它更容易地去计算,因为我们不想将所有在 V 中的词的概率加起来。 重要性采样方法 (责任编辑:本港台直播) |