|
另一个区别就是训练目标:word2vec 和 GloVe 都是用来生成广泛语义关系的词嵌入模型,这对许多下游任务有用;而这种方式训练的词嵌入对不依赖于这种语义关系的任务并无太多帮助。相反,常规的神经网络对于某个特定任务生成的词嵌入在别的任务往往功能有限。值得注意的是,一个依赖于语言建模这样的语义关系的任务能够生成类似于词嵌入模型的嵌入,这一点我们将在下节探讨。 额外说明一点,word2vec 和 Glove 之于自然语言处理,也许就像是 VGGNet 之于计算机视觉,亦即一个普通的权重初始化——它能提供有用特征,而且无需长时间训练。 比较不同的模型,我们可以设想如下的标准:我们设想一串来自词汇库 V(其大小为|V|)的包含 T 个训练单词的的字符序列 w_1,w_2,w_3,?,w_T。 想象我们的模型是一段包含 n 个单词的文段。我们将每一个单词与一个 d 维的输入向量 v_w(嵌入层中的同名词嵌入)和一个输出向量 v_w'(另一个词表征,其作用下面很久就会介绍)联系在一起。最终,对于每一个输入 x,我们相对于模型参数θ和模型输出分数 f_θ(x) 来优化目标函数 J_θ。 语言建模上的一项注意 词嵌入模型和语言模型联系紧密。对语言模型的质量评价基于它们学习 V 词汇库的词语概率分布的能力。事实上,许多最新的词嵌入模型一定程度上尝试预测序列下一个会出现的词。另外,词嵌入模型的评价通常运用困惑度(perplexity)——一个从语言建模借来的基于交叉熵的评价标准。 在我们进入词嵌入模型的众多细节之前,让我们简单介绍一些语言建模的基础知识。 总体而言,语言建模力求在给定之前的词语的情况下,计算一个词语 w_t 的出现概率,atv,也就是 p(w_t|w_{t?1},?w_}t?n+1})。运用链式法则和马尔可夫假设,我们就可以近似地通过之前出现的 n 个词得到每个词的概率乘积,从而得到整个句子或整篇文章的乘积: 在基于 n 元的语言模型中,直播,我们可以用一个词的组分的 n 元的频率(frequency)来计算这个词的概率:
设置 n=2 产生二元模型,而 n=5 和 Kneser-Ney 则一同呈现平滑的五元模型——平滑的五元模型在语言建模中是公认的的一个强有力基准线。更多的细节,敬请参照斯坦福大学的演讲课件。 在神经网络中,我们通过大家熟知的 Softmax 层来计算相同的目标函数:
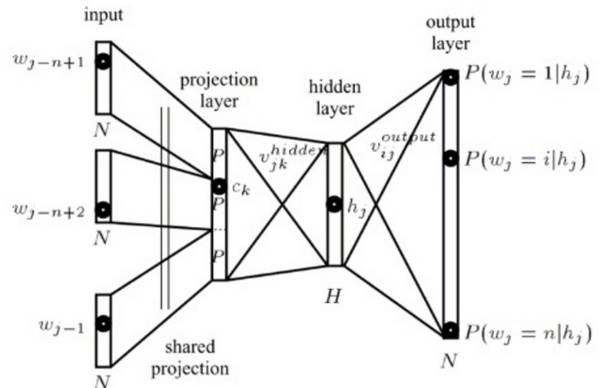
内积 h^T v'_{w_t} 计算了词 w_t 的未标准化的对数-概率(log-probability),我们用在词汇库 V 中的所有词的对数-概率之和来把它标准化。h 是它的倒数第二层(见图 1 前向传播网络的隐藏层)的输出向量,而 v'_w 就是词 w 的输出嵌入,亦即在 softmax 层的权重矩阵中的表征。注意虽然 v'_w 可以表征词 w,但它是从输入词嵌入 v_w 独立学习的,因为向量 v'_w 和向量 v_w 的相乘对象是不同的(v_w 和索引向量相乘,v′_w 和 h 相乘)。
图 1: 一个自然语言模型(Bengio 等人,2006 年) 我们需要计算每个词 w 在神经网络输出层的概率。想要高效地做到这一点,我们将 h 和一个权重矩阵相乘,这个权重矩阵每行都是对于在 V 中出现的词 w 所得的 v′_w。我们随后将得到的向量(我们通常称之为 logit,也就是前一层的输出)以及 d=|V| 传入到 softmax 层,softmax 层则把词嵌入「压扁」成一个词汇库 V 里面词的概率分布。 注意 softmax 层(对比于之前的 n 元计算)仅仅隐式地考虑之前出现的 n 个词。长短时记忆模型(Long Short-term Memory, 英文简称 LSTM),通常用来作自然语言处理模型,将这些词编码成状态 h。我们在下一章将会介绍的 Bengio 的自然语言模型,则是把之前的 n 个词通过一个前向传播层传入。 请大家记住这个 softmax 层,许多后续介绍的词嵌入模型都将或多或少地运用它。运用这个 softmax 层,模型将尝试着在每一时刻 t 都最大化正确预测下一词的概率。于是,整个模型尝试最大化整个数据集的平均对数-概率:
相似地,运用链式法则,模型的训练目标通常是最大化整个语料库的所有词相对于之前 n 个词的平均对数-概率: (责任编辑:本港台直播) |